Projet Boumeh : Conduite Autonome
Overview
Le projet Boumeh est un système de conduite autonome basé sur l'apprentissage de bout en bout (End-to-End Learning). L'idée est simple : le véhicule apprend à se diriger uniquement à partir de ce qu'il voit avec ses caméras, sans avoir besoin de cartes détaillées ou de capteurs LiDAR coûteux. Le réseau de neurones reçoit les images des trois caméras (gauche, centre, droite) et prédit directement l'angle de braquage à appliquer. Les données d'entraînement ont été collectées en utilisant trois protocoles de contrôle différents : MPC (Model Predictive Control), PID (contrôleur proportionnel-intégral-dérivé), et Teleop (télé-opération manuelle dans la simulation), ce qui permet de capturer différents styles de conduite et d'enrichir le dataset avec des trajectoires variées.
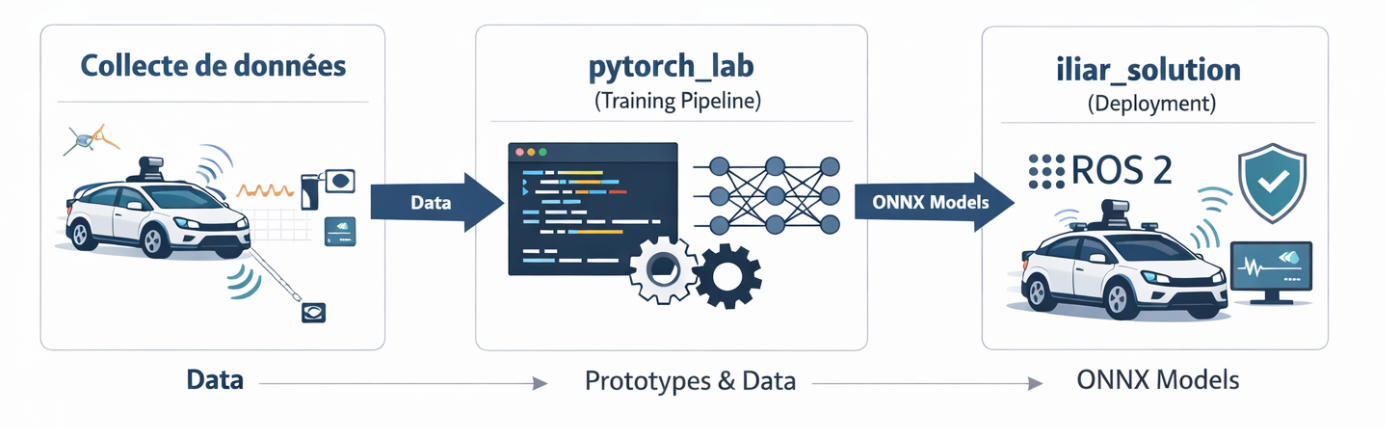
Le workflow du projet se divise en plusieurs phases. D'abord, la collecte de données : notre code propose trois protocoles de contrôle (MPC, PID, et Teleop), mais c'est le MPC (Model Predictive Control) qui a été utilisé pour générer les trajectoires d'entraînement. Ensuite vient la phase d'expérimentation dans des notebooks Jupyter, où on teste rapidement différentes architectures neuronales (ResNet, Transformers). Une fois les résultats validés, on passe au pipeline d'entraînement structuré qui garantit la reproductibilité et la traçabilité des modèles. Enfin, le déploiement : le modèle est intégré dans un système ROS 2 dans la simulation, avec toute la logique de sécurité nécessaire pour gérer le passage de contrôle entre l'IA et le Teleop.
Architecture Globale
Le projet est structuré comme un pipeline industriel, divisé en trois phases distinctes correspondant aux trois espaces de travail du repository.
boumeh
├── iliar_solution
│ ├── config
│ ├── iliar_solution # Code source Python des nœuds ROS 2
│ ├── launch
│ ├── models
│ └── training
├── NotebookLAB
│ ├── Data
│ ├── Models
│ ├── Notebooks # Notebooks Jupyter (R&D)
│ └── Resources
├── pytorch_lab
│ ├── logs
│ └── src
│ └── torchtmpl # Code source du pipeline d'entraînement
Pas de panique !
Ça fait beaucoup de dossiers d'un coup, on sait. Mais ne vous inquiétez pas ! Nous allons décortiquer chaque module, chaque fichier et chaque ligne de code (ou presque) dans les sections suivantes. Détendez-vous, prenez un café ☕, et laissez-vous guider. Tout va s'éclaircir, promis !
Phase 1 : Collecte de Données (ROS 2)
Cette première phase est dédiée à la constitution du dataset d'entraînement. Nous avons implémenté plusieurs protocoles, notamment le Teleop (teleop_command.py) et le PID (path_follower.py), mais la méthode retenue pour la collecte est principalement le MPC (mpc.py). Ce contrôleur prédictif est reconnu pour générer des trajectoires fluides et naturelles, offrant une "vérité terrain" idéale pour le réseau de neurones. L'ensemble de ce pipeline d'acquisition (lancement de la simulation, du contrôleur choisi et du nœud d'enregistrement record_optimized.py) est centralisé et orchestré par un unique launcher : datarecord.launch.xml.
Phase 2 : Entraînement et Scalabilité (PyTorch)
L'objectif de cette phase est d'entraîner un modèle d'IA capable de conduire par imitation (Behavioral Cloning). Dans cette approche End-to-End, le réseau de neurones apprend à mapper directement les pixels des caméras vers une commande de direction, sans étape intermédiaire de détection d'objets. Il cherche à cloner le comportement fluide et optimal observé dans le dataset du MPC.
Pour structurer cette recherche et garantir la robustesse des résultats, nous avons divisé le travail en deux espaces :
-
Exploration R&D (
NotebookLAB) : C'est notre laboratoire d'expérimentation rapide. Ici, nous utilisons des notebooks Jupyter pour visualiser les données, analyser les distributions statistiques (biais de braquage), et prototyper de nouvelles architectures (CNN, Vision Transformers) de manière interactive. -
Industrialisation (
pytorch_lab) : Pour passer à l'échelle, nous migrons les modèles validés vers cette structure rigoureuse. Elle est conçue pour la scalabilité, permettant de lancer plusieurs entraînements en parallèle sur un cluster de calcul via Slurm. C'est ici que se joue la performance finale, avec une gestion fine des hyperparamètres et des logs d'entraînement.
Phase 3 : Déploiement et Évaluation (ROS 2 / ONNX)
La finalité du projet est de faire rouler la voiture de manière autonome. Pour cela, les modèles entraînés (PyTorch) sont d'abord exportés au format universel ONNX pour garantir une inférence rapide et compatible.
Une fois exporté, le modèle est chargé par le nœud critique ROS 2 : autopilot.py. Ce nœud récupère les flux des caméras, exécute l'inférence en temps réel, et publie les commandes de contrôle. La sécurité est assurée par le command_mux.py qui donne toujours la priorité à l'humain.
Pour valider les performances, nous utilisons des launchers dédiés :
-
autopilot.launch.xml: Active le mode conduite autonome. -
evaluation.launch.xml: Lance la voiture avec le nœudevaluator.py, qui compare en temps réel la conduite de l'IA par rapport à la trajectoire idéale, fournissant une mesure objective de la qualité du modèle.
Pour aller plus loin
Chaque étape mentionnée ici (Collecte, Entraînement, Déploiement) est détaillée dans sa propre section dédiée dans la barre de navigation.
Chaque phase de notre pipeline correspond à une page de documentation spécifique. Suivez le guide !